
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 자바
- 네트워크
- vlan
- 인공지능
- abex'crackme
- 온프레미스
- 스위치
- Reversing
- RIP
- Mac
- 리버싱
- bastion host
- AI
- cmd
- Java
- CISCO
- 크롤러
- docker
- vector
- 라우터
- 머신러닝
- 암호학
- dreamhack
- 머신러닝 프로세스
- Firewall
- Repository
- STP
- Python
- Screening Router
- AWS
Archives
- Today
- Total
Haekt‘s log
[Python3] 정규표현식을 이용한 크롤러 만들기 본문
*참고
https://haekt-log.tistory.com/78
[Python3] 간단한 웹 크롤러 만들기
웹사이트의 html 및 js 코드를 크롤링 해보자. - 필요한 사전 지식 크롤링 : WWW 를 탐색해 나가는 행위를 말한다. 파싱 : 자연어, 컴퓨터 언어 등의 문자열을 분석하는 프로세스를 말한다. 파서 : 파
haekt-log.tistory.com
- 라이브러리 설명
re : 정규표현을 처리할 수 있게 하는 Python 라이브러리.
- 정규표현식
(?<=표현식1)표현식2 : 표현식2 앞의 문자열이 표현식1과 매치되면 표현식2 매치.
표현식1을 포함하는 문자열에서 표현식2 부분을 저장함.
\\ : 바로 앞의 기호를 문자로 인식하게 한다.
(.*) : 여러개의 모든 문자를 의미한다.
- 코드 예시 (1)
_link 변수에 <a href> 부분만을 따오는 정규표현식을 작성했다.
import re
_link = "(?<=a href=\\')(.*)(?=\\'><img)"
link_pattern = re.compile(_link)
list1=["< a href='A1?=a2'><img>","< a href='B1?=b2'><img>","< a href='C1?=c2'><img>","< a href='D1?=d2'><img>","< a href='E1?=e2'><img>"]
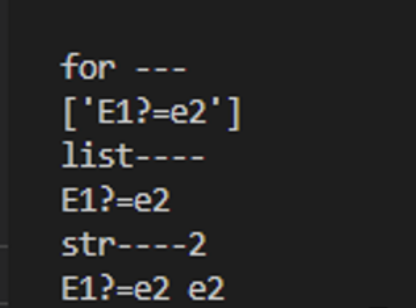
for l1 in list1:
print('\\nfor --')
down_link = link_pattern.findall(str(l1))
if(down_link):
print(down_link)
print('list----')
down_link = down_link[0]
print(down_link)
print('str----2')
md5_hash = down_link.split('=')[1]
print(down_link, md5_hash)- 결과
- 코드 예시 (2)
해당 코드는 특정 사이트에서 md5 값으로 이루어진 파일을 다운로드 하는 코드이다.
import urllib.request
from bs4 import BeautifulSoup
import re
# a href=" .... "><img 부분을 찾고 .* 부분 뽑아냄.
# \\" 는 " 를 문자처리하기 위함
_link = '(?<=a href=\\")(.*)(?=\\"><img)'
# ( md5 형식에 맞는 32 개의 문자 + </a> )
_md5 = '[a-z0-9]{32}(?=</a>)'
link_pattern = re.compile(_link)
def get_html(url):
try:
html = urllib.request.urlopen(url).read().decode('utf-8')
except:
return None
if(html==None):
print("url get error")
else:
bsobj=BequtifulSoup(html,'html5lib')
# html 중 table 부분을 가져오고, 그중 td 부분을 리스트로 불러옴
# 불러온 리스트를 td 변수에 순서대로담아 리스트 크기만큼 반복한다.
for td in bsobj.find('table').findAll(str('td')):
# re라이브러리의 findall 함수를 사용하여,
# td변수에 담긴 값에서 정규표현식에 해당하는 값을 골라내 리스트로 변수에 저장
down_link = link_pattern.findall(str(td))
# 골라낸 값이 존재할 경우
if down_link:
# ['./files.php?file=86927f...0675'] -> ./files.php?file=86927f...0675
# down_link는 리스트이므로, 문자값으로 바꿔서 초기화
down_link = down_link[0]
# 문자열로 바뀐 값을 =를 기준으로 나누어 저장.
# ['./files.php?file', '86927f...0675'] 에서 1인 86927f...0675 부분을 저장
md5_hash = down_link.split('=')[1]
print down_link, md5_hash
return bs obj
url = "http://---"
get_html(url)
'언어 > Python' 카테고리의 다른 글
| [Python3] 간단한 웹 크롤러 만들기 (0) | 2023.03.06 |
|---|---|
| [Python2] SyntaxError: Non-ASCII character '\xec' in file ... (0) | 2023.03.05 |
| [Python3] Linux 디렉토리 안의 파일 리스트 뽑아오기. (0) | 2023.03.05 |
'언어/Python' Related Articles
more


Comments